

Discover the proven ML algorithms driving 2025 AI: trees, boosting, transformers, and more. Learn what to use, when, and why it matters.
- December 2025: Why algorithms still decide winners
- A simple map of machine learning problems
- Linear regression and regularization
- Logistic regression for classification
- Naive Bayes for fast text and rules-like decisions
- k-Nearest Neighbors for similarity search
- Decision trees: the interpretable workhorse
- Random forests: robust performance with low drama
- Gradient boosting: XGBoost, LightGBM, CatBoost
- Support Vector Machines: the margin mindset
- K-means and modern clustering
- PCA and dimensionality reduction
- Neural networks: multilayer perceptrons and CNNs
- Transformers and foundation models
- Reinforcement learning and bandits for agentic AI
- Anomaly detection and fraud signals
- How to choose and ship an algorithm
- Conclusion: Build a confident algorithm toolbox
December 2025 feels like a breakthrough moment for AI. Yet the most successful teams still win with fundamentals. They choose the right algorithm. They validate it with discipline. They ship it with care.
AI adoption is also accelerating fast. The 2025 AI Index reports that 78% of organizations used AI in 2024, up from 55% the year before. It also highlights strong momentum in generative AI investment. (Stanford HAI) Furthermore, McKinsey reported in May 2024 that 65% of respondents said their organizations were regularly using gen AI. (McKinsey & Company) That is exciting. It is also a little scary. Because real value depends on correct choices, not hype.
This guide focuses on key machine learning algorithms you should know. It is practical. It is high trust. It is built for real business outcomes in late 2025.
December 2025: Why algorithms still decide winners
The 2024 to 2025 reality check
Many AI systems look magical at first. Then real data arrives. Costs show up. Latency gets critical. Stakeholders demand verified results. At that point, algorithm choice becomes vital.
Additionally, “agentic AI” is rising fast. McKinsey’s 2025 survey notes that 23% of respondents report scaling an agentic AI system somewhere in the enterprise, while more are experimenting. (McKinsey & Company) Agents still need classic ML. They need ranking, classification, anomaly detection, and bandits. So the “old” algorithms become immediately relevant again.
The practical promise
Here is the rewarding truth. You do not need a single perfect model. You need a proven stack. You need strong baselines, strong evaluation, and authentic monitoring. Consequently, learning core algorithms gives you durable power.
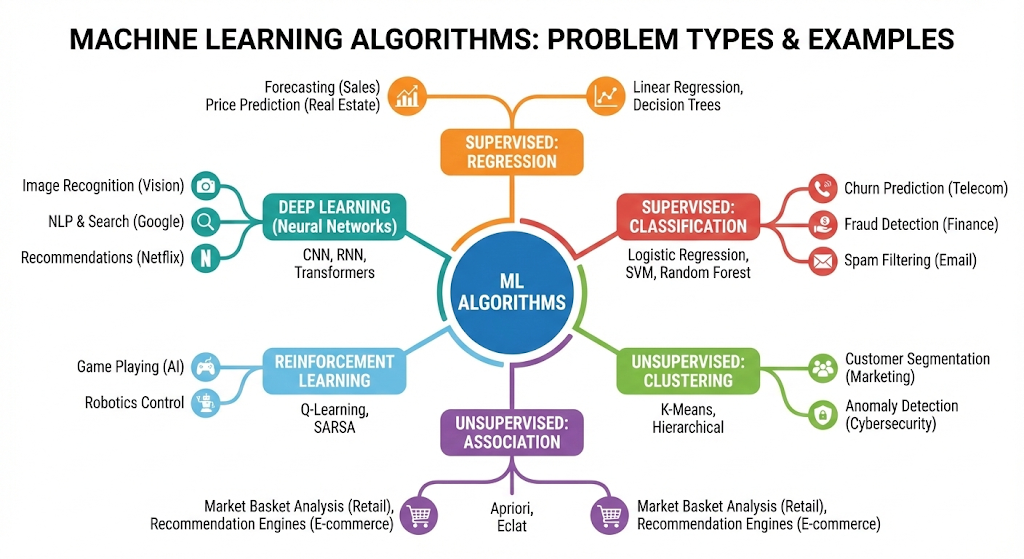
A simple map of machine learning problems
Supervised, unsupervised, and reinforcement learning
Most business ML sits in supervised learning. You predict a label or a number. Think fraud yes or no. Think credit risk score. Think demand forecast.
Unsupervised learning looks for structure without labels. It powers segmentation, clustering, and anomaly discovery. Meanwhile, reinforcement learning learns through trial and feedback. It is now tied to personalization, bidding, and agent behavior.
Data shape matters more than people admit
Tabular data is rows and columns. It dominates finance, ops, and sales. Text, images, and audio often need deep learning. Time series needs careful validation. Graph data brings special methods.
However, no rule is guaranteed. Boosted trees can beat neural nets on tabular data. A simple linear model can beat an overfit transformer on small data. That is why this guide stays balanced.
Linear regression and regularization
When it shines
Linear regression is the classic baseline for numeric prediction. It is fast. It is interpretable. It is easy to debug. That makes it an essential tool in 2025.
It works well when relationships are roughly linear. It also handles many features with the right regularization. Regularization is a critical upgrade. It protects you from overfitting.
What can go wrong
Linear regression can look accurate, then fail in production. Outliers can distort it. Leakage can trick it. Nonlinear patterns can overwhelm it.
Additionally, multicollinearity can cause unstable coefficients. Ridge regression helps. Lasso can also help by driving some coefficients to zero. Elastic Net blends both, which is often a safe, rewarding default.
Logistic regression for classification
Why it is still a certified baseline
Logistic regression is a powerful classifier. It outputs probabilities. It trains quickly. It is easy to explain to executives. That combination is rare and valuable.
In many real systems, logistic regression is the first verified model you can trust. It sets a baseline you can beat. It can also be the final model when speed and clarity matter.
Calibration and decision thresholds
A probability is not a decision. You still choose a threshold. That choice must match your risk. For fraud, you might prefer higher recall. For approvals, you might prefer higher precision.
Furthermore, probability calibration matters. A model can rank well but give misleading probabilities. Techniques like Platt scaling or isotonic regression can be vital when decisions are high stakes.
Naive Bayes for fast text and rules-like decisions
The “naive” assumption that still works
Naive Bayes is shockingly effective. It assumes features are conditionally independent. That assumption is not true in most real data. Still, it often works well for text classification.
It is fast. It is stable. It can be a breakthrough baseline for spam, support tickets, and topic tagging. It is also great when training data is limited.
Where it breaks
Naive Bayes struggles when feature interactions matter. It also suffers when you need complex boundaries. However, as a quick and proven first pass, it remains a critical algorithm to know.
k-Nearest Neighbors for similarity search
Why it feels intuitive
k-NN predicts based on the closest examples. It is easy to understand. It is also surprisingly strong for some tasks, like small tabular datasets or pattern matching.
In December 2025, similarity is also booming. Vector search is everywhere. That makes the k-NN idea feel immediate and relevant.
How to keep it fast
Plain k-NN can be slow at scale. You often need approximate nearest neighbor methods. Libraries and vector databases handle this with indexing.
Additionally, distance choice matters. Cosine distance is common for embeddings. Euclidean distance is common for normalized tabular features. Getting this right is a rewarding win.
Decision trees: the interpretable workhorse
Splits, impurity, and pruning
A decision tree splits data into branches. It tries to increase purity at each step. It can capture nonlinear patterns. It can also provide clear explanations.
Yet single trees are fragile. They overfit easily. Pruning is critical. Depth limits are vital. A tree that is too deep becomes noisy and untrusted.
How to avoid brittle trees
Use trees when interpretability matters. Keep them small. Validate with cross-validation. Watch for leakage. Also check stability across time splits.
Consequently, many teams use trees mainly as building blocks for ensembles. That is where they become truly powerful.
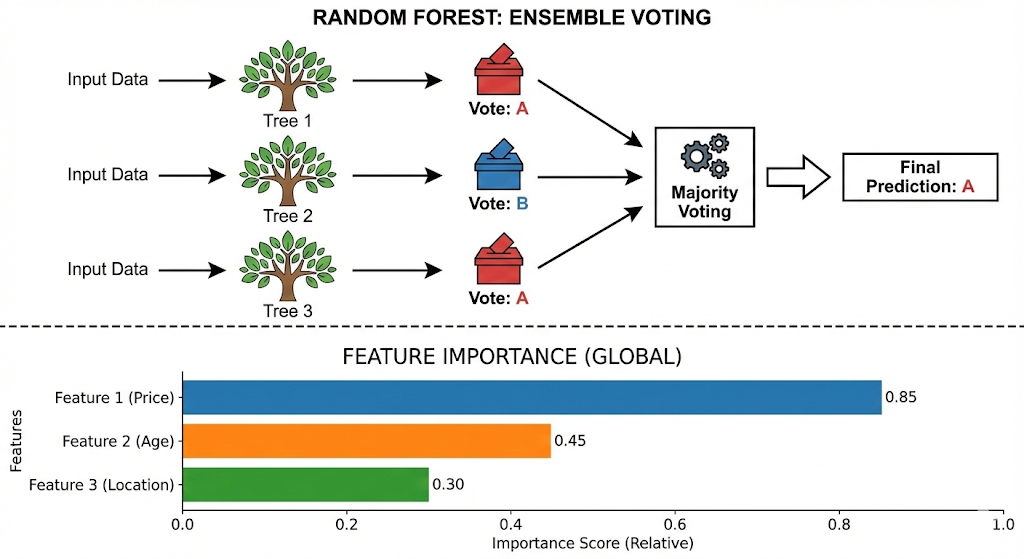
Random forests: robust performance with low drama
Bagging and feature randomness
Random forests combine many trees. Each tree sees a bootstrap sample. Each split uses a subset of features. This reduces variance. It improves stability.
Random forests are proven for tabular data. They handle nonlinear patterns well. They also provide useful feature importance signals.
What to tune first
Start with number of trees. Then tune max depth. Also tune minimum samples per leaf. Those controls reduce overfitting. They also improve generalization.
Gradient boosting: XGBoost, LightGBM, CatBoost
The core idea of boosting
Boosting trains models sequentially. Each new model focuses on the errors of the last model. This is a breakthrough concept. It produces strong learners from weak ones.
Gradient Boosted Decision Trees are now a gold standard for tabular ML. Google’s ML materials describe gradient boosting as iteratively combining weak models, typically trees, to build a strong predictor. (Google for Developers) That description matches how most production systems use it today.
Why boosted trees dominate tabular data
Boosted trees often win on structured data. They handle mixed feature types. They cope with missing values in many implementations. They also perform well with modest feature engineering.
LightGBM is famous for speed on large datasets. Microsoft Research introduced it as a highly efficient gradient boosting decision tree approach, with strong training speed claims in experiments. (Microsoft) XGBoost remains widely used, with modern tutorials still appearing in peer reviewed venues in 2025. (PMC)
Practical tuning checklist
Start simple. Use a strong validation scheme. Then tune learning rate, number of trees, and max depth. Add subsampling for stability. Monitor overfitting with early stopping.
Additionally, watch class imbalance. Use class weights or scale_pos_weight. For ranking problems, use ranking objectives. For text or images, do not force boosted trees if embeddings are weak.
Support Vector Machines: the margin mindset
Linear SVM vs kernel SVM
SVM tries to find a boundary with maximum margin. That margin creates strong generalization in many cases. It is elegant. It is also still useful.
Linear SVM is fast for high dimensional sparse data. Text classification is a classic example. Kernel SVM can model complex boundaries. Yet kernels can be costly at scale.
When SVM is a clever choice
SVM is great when data is clean and medium sized. It is also strong when features are already meaningful, like TF-IDF vectors.
However, SVM can be tricky to tune. Scaling features is vital. Choosing kernels can be risky. Still, for the right problem, it is a rewarding and proven tool.
K-means and modern clustering
K-means for quick segmentation
K-means is a simple clustering method. It groups points into K clusters. It is fast. It is easy to explain.
K-means is perfect for quick market segmentation. It also works for document grouping with embeddings. Yet it assumes roughly spherical clusters. That can be a critical limitation.
DBSCAN and HDBSCAN for messy clusters
Real data is messy. DBSCAN finds clusters by density. It can detect noise. It does not require K.
Additionally, HDBSCAN is a strong modern extension. It can handle variable density better. Use these when clusters are irregular.
PCA and dimensionality reduction
PCA for speed and sanity
PCA compresses features into fewer components. It captures the strongest variance directions. It is useful for noise reduction. It is also useful for visualization.
PCA can also stabilize downstream models. It can make training faster. It can reduce overfitting risk in high dimensional spaces.
UMAP and t-SNE for visualization
UMAP and t-SNE are popular for 2D maps. They can reveal structure in embeddings. They are compelling. They are also easy to misuse.
Consequently, treat them as exploratory tools. Do not judge real performance from a pretty plot. Validate with metrics.
Neural networks: multilayer perceptrons and CNNs
Backprop and gradient descent basics
Neural networks learn by gradient descent. Backprop computes gradients efficiently. This is a foundational idea. It powers modern AI.
Neural nets shine with large data and complex patterns. They can also merge many signals. That makes them vital for multimodal systems in 2025.
CNNs for vision and audio
CNNs are still essential for images. They capture local patterns well. They run efficiently on GPUs. They also remain strong for audio spectrograms.
However, vision transformers are rising too. Still, CNN knowledge is certified value. Many real pipelines use both, depending on constraints.
Transformers and foundation models
Attention, context, and scaling
Transformers changed everything. They use attention to model relationships across tokens. That enables long range context. It also enables scaling.
In the 3Blue1Brown lesson on transformers, the publication date is April 1, 2024, and it was updated in November 2025. (3blue1brown.com) That timeline matches how fast this field moves. It is thrilling and relentless.
Fine-tuning, RAG, and vector databases
By December 2025, many teams use foundation models plus classic ML. They fine-tune small models. They use RAG for grounded answers. They store embeddings in a vector database.
Additionally, you still need ranking algorithms. You still need classification. You still need anomaly detection. That is why this guide blends old and new.
[YouTube Video]: Visual, intuitive explanation of transformers and GPT style models, ideal for understanding attention and context windows
Reinforcement learning and bandits for agentic AI
Q-learning and policy gradients
Reinforcement learning optimizes long term reward. Q-learning learns action values. Policy gradients learn a policy directly. Both are powerful.
RL can be hard to stabilize. Simulation quality is critical. Reward design is vital. Without that, the system can behave in surprising ways.
Contextual bandits for practical experimentation
Bandits are a simpler, proven tool. They help choose among options while learning from feedback. This is perfect for recommendations, notifications, and offer selection.
Furthermore, bandits fit agentic AI workflows. They balance exploration and exploitation. They are efficient. They can be safer than full RL in many business settings.
Anomaly detection and fraud signals
Isolation Forest and one-class methods
Anomaly detection finds rare patterns. Isolation Forest isolates points with random splits. It works well in high dimensional spaces. It is also fast.
One-class SVM is another option. It can be effective with the right kernel. Yet it can be sensitive. Scaling and tuning are essential.
Autoencoders for rare patterns
Autoencoders learn to reconstruct normal data. High reconstruction error can signal anomalies. This can be strong in complex sensor data.
However, evaluation is tricky. Labels are scarce. False positives can be costly. Consequently, monitoring and human feedback loops are critical.
How to choose and ship an algorithm
Metrics and cross-validation
Always start with a baseline. Then improve step by step. Use the right metric. For classification, track precision, recall, and AUC. For regression, track MAE and RMSE.
Cross-validation is powerful. Yet time series needs time based splits. Grouped data needs grouped splits. If you ignore this, results will be misleading.
Data leakage, drift, and monitoring
Leakage is the silent killer. It creates fake performance. Remove future info. Remove ID like fields. Validate like production.
Drift is also real in 2025. Markets change. Users change. Sensors degrade. Therefore, monitoring is vital. Track data statistics. Track prediction distributions. Track business KPIs.
A short learning plan that actually works
First, master linear and logistic regression. Next, learn trees, random forests, and gradient boosting. Then add clustering and PCA. After that, learn neural nets and transformers.
Meanwhile, keep shipping small projects. Make each project measurable. Document failures. This approach is proven and rewarding.
Conclusion: Build a confident algorithm toolbox
You do not need to memorize everything. You need a clear toolbox. You need a critical sense of tradeoffs. You need verified evaluation habits.
By December 2025, the most successful AI teams combine classic ML with modern foundation models. They use boosted trees for tabular wins. They use transformers for language and multimodal tasks. They add bandits for decision loops. That mix is powerful, practical, and future proof.
Sources and References
- Artificial Intelligence Index Report 2025 PDF
- The 2025 AI Index Report page
- McKinsey: The state of AI in early 2024
- McKinsey: The State of AI Global Survey 2025
- Google Developers: Intro to Gradient Boosted Decision Trees
- TensorFlow Decision Forests: Getting started tutorial
- IBM: What is Random Forest
- IBM: What is Support Vector Machine
- Microsoft Research: LightGBM paper page
- TensorFlow: GradientBoostedTreesModel API docs
- 3Blue1Brown lesson page: Transformers, the tech behind LLMs
- 2025 tutorial paper on XGBoost (PubMed Central)
- YouTube: TF Decision Forests gradient boosted trees video
- YouTube: 3Blue1Brown Transformers video
- YouTube: MIT 6.S191 Transformers lecture





